Разделы презентаций
- Разное
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Геометрия
- Детские презентации
- Информатика
- История
- Литература
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Архитектура AMD K8 процессоров AMD Athlon64, Athlon64FX и Opteron
Содержание
- 1. Архитектура AMD K8 процессоров AMD Athlon64, Athlon64FX и Opteron
- 2. СодержаниеВведениеОсновные характеристики процессоров семейства AMD K8Архитектура процессоров
- 3. Введение С выходом процессоров семейства Athlon в 1999
- 4. Основные характеристики процессоров семейства AMD K8
- 5. Архитектура процессоров AMD K8 Отличия ядра Athlon 64 от современных Athlon XPАрхитектура х86-64РегистрыАдресацияВычисленияСовместимостьЯдро процессора
- 6. Отличия ядра Athlon 64 от современных Athlon
- 7. Архитектура х86-64 Вот уже достаточно долгое время
- 8. Архитектура х86-64 Самое время задаться вопросом
- 9. Архитектура х86-64 научные вычисления. Здесь ценен
- 10. Регистры В AMD64 к имеющимся регистрам было
- 11. Регистры Следующее по
- 12. Адресация
- 13. Адресация Оригинальный IBM PC/XT мог иметь до
- 14. Адресация Трансляция линейных адресов в физические:
- 15. Адресация Видно, что трансляция адреса стала четырехуровневой
- 16. Адресация Предвидя возникновение этой проблемы, инженеры добавили
- 17. Вычисления Операции над 64-битными числами ведутся в
- 18. Вычисления Функция 64-битного умножения в x86: x86_mul_64x64
- 19. Вычисления Функция 64-битного умножения в AMD64: amd64_mul_64x64
- 20. Вычисления Кстати, 64 бита - не предел.
- 21. Вычисления Очевидно четырехкратное преимущество последних. Кстати Athlon 64
- 22. Совместимость Главный фактор, объясняющий удивительный успех архитектуры
- 23. Совместимость
- 24. Совместимость Большинство 64-битных операционных систем будут поддерживать
- 25. Совместимость
- 26. Совместимость Преобразования не столь накладны, как кажутся,
- 27. Ядро процессора Блок-схемаКэш инструкций - I-cacheКэш данных
- 28. Блок-схема
- 29. Кэш инструкций - I-cache Его размер остался
- 30. Кэш данных - D-cache D-cache, он
- 31. Буфер быстрого преобразования адреса – TLB Translation
- 32. Кэш память второго уровня - L2 cache
- 33. Блок предсказания переходов – BTB (Branch Target
- 34. Декодер Декодер подвергся наибольшей переработке. Собственно, своим
- 35. Контроллер памяти Интегрированный контроллер памяти — это
- 36. Контроллер Hyper Transport HyperTransport является протоколом последовательной
- 37. Контроллер Hyper Transport Кроме того, раз уж
- 38. Контроллер Hyper Transport Хочется также продемонстрировать, насколько
- 39. Конструктивное исполнение процессоров AMD K8 На
- 40. Socket 754 Этот разъем предназначен для установки
- 41. Socket 940 В отличие от S754 этот
- 42. Socket 939 1 июня 2004г. AMD анонсировала
- 43. Socket 939 Для большей наглядности приведем изображения
- 44. Чипсет AMD 8000ATI Radeon Xpress 200/PVIA K8T890NVIDIA nForce 4
- 45. AMD 8000 Давно известно, что часто именно
- 46. AMD 8000 Ведь что осталось из функций
- 47. AMD 8000
- 48. AMD 8000 Вместо одного чипсета для мейнстрим
- 49. ATI Radeon Xpress 200/P
- 50. ATI Radeon Xpress 200/P
- 51. ATI Radeon Xpress 200/P
- 52. ATI Radeon Xpress 200/P
- 53. VIA K8T890
- 54. VIA K8T890 Блок-схема VIA K8T890:
- 55. VIA K8T890
- 56. VIA K8T890
- 57. NVIDIA nForce 4
- 58. NVIDIA nForce 4
- 59. NVIDIA nForce 4
- 60. NVIDIA nForce 4
- 61. NVIDIA nForce 4
- 62. NVIDIA nForce 4
- 63. NVIDIA nForce 4 Сводная таблица по основным характеристикам семейства чипсетов NVIDIA nForce 4:
- 64. Последние разработки AMD Технология PacificaТехнология PowerNow! Dual
- 65. Технология Pacifica Технология Pacifica разрабатывается с
- 66. Технология Pacifica
- 67. Технология PowerNow! Технология энергосбережения
- 68. Dual Stress Liner
- 69. Dual Stress Liner
- 70. 90 нм техпроцесс в Athlon 64 Начиная
- 71. 90 нм техпроцесс в Athlon 64 Для
- 72. 90 нм техпроцесс в Athlon 64 Объясняется
- 73. 90 нм техпроцесс в Athlon 64
- 74. 90 нм техпроцесс в Athlon 64
- 75. 90 нм техпроцесс в Athlon 64
- 76. 90 нм техпроцесс в Athlon 64
- 77. 90 нм техпроцесс в Athlon 64
- 78. 0.065 мкм техпроцесс Производство 0.065 мкм процессоров
- 79. Мобильные процессоры Недавно запущенный в серийное производство
- 80. Мобильные процессоры
- 81. Мобильные процессоры
- 82. Двухядерные процессоры AMD Как известно, оба ведущих
- 83. Двухядерные процессоры AMD Первые процессоры от AMD,
- 84. Двухядерные процессоры AMD 31 августа 2004 на
- 85. Двухядерные процессоры AMD В заключение, несколько слов
- 86. Заключение Впервые с момента появления набора команд 3DNow!
- 87. P.S.
- 88. Методика использования демонстрационного пособия Представленное пособие может быть
- 89. Контрольные вопросы В процессе исследования представленного материала
- 90. Контрольные вопросы 6. Какова пропускная способность шины
- 91. Скачать презентанцию
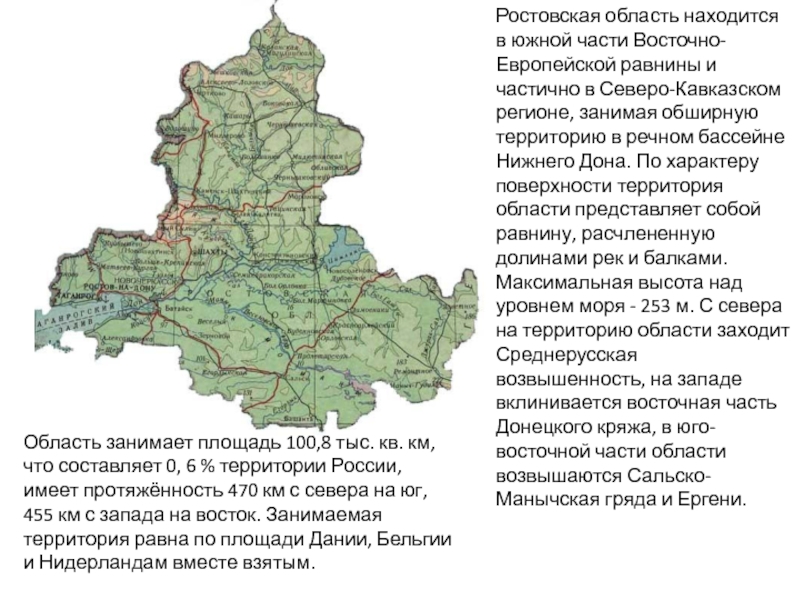
СодержаниеВведениеОсновные характеристики процессоров семейства AMD K8Архитектура процессоров AMD K8Конструктивное исполнение процессоров AMD K8Набор системной логики - чипсетПоследние разработки AMDЗаключениеМетодика использования демонстрационного пособияКонтрольные вопросы
Слайды и текст этой презентации
Слайд 1Архитектура AMD K8 процессоров
AMD Athlon64, Athlon64FX и Opteron.
Доцент кафедры ИТОиУ
Горшенин А. Ю.

Слайд 2Содержание
Введение
Основные характеристики процессоров семейства AMD K8
Архитектура процессоров AMD K8
Конструктивное исполнение
процессоров AMD K8
Набор системной логики - чипсет
Последние разработки AMD
Заключение
Методика использования
демонстрационного пособияКонтрольные вопросы

Слайд 3Введение
С выходом процессоров семейства Athlon в 1999 году, конкуренция на
процессорном рынке значительно обострилась. Прогрессивная архитектура этого CPU позволила AMD
достаточно продолжительное время составлять Intel достойную конкуренцию и предлагать не только не уступающие по быстродействию процессоры, но и зачастую даже более быстрые. Однако в последнее время поддерживать паритет с Intel для AMD стало гораздо труднее. За время жизни архитектуры Athlon Intel перешел с архитектуры Pentium III к абсолютно новой архитектуре Pentium 4, да еще и усовершенствовал ее, увеличив кэш второго уровня и нарастив частоту системной шины. Athlon также подвергался усовершенствованиям, однако все они не носили кардинального характера: разгон шины, увеличение L2 кеша, поддержка SSE. В итоге, на сегодняшний день Intel практически удалось немного оторваться от конкурента: частоты Pentium 4 растут как на дрожжах, а AMD достигла «потолка» по частотам архитектуры Athlon. Однако AMD заготовила сильный ход, который вновь коренным образом изменил ситуацию на процессорном рынке. Компания вывела на рынок CPU для настольных PC новый процессор – Athlon 64.Впервые о "64-битности" заговорили еще во времена первого Pentium (1993). Однако вскоре выяснилось, что 64-битной стала шина данных, тогда как логика самого процессора осталась 32-битной. Новый интерес к 64-битной архитектуре возник после анонса процессора Merced (1997), представленного в конце 1999 года под торговой маркой Itanium. К сожалению, существующие 32-битные программы работали на нем медленнее Celeron'а, стоящего, к тому же, в несколько раз дешевле. Это поставило крест на домашнем и офисном применении Itanium'а.Но время шло, и вот "магические" 64 бита опять на слуху. На сей раз виновником торжества стала архитектура AMD64 и основанные на ней процессоры: Athlon 64, Athlon FX и Opteron.

Слайд 4Основные характеристики процессоров семейства AMD K8 Приведем сводную таблицу параметров процессоров
AMD K8 в сравнении с процессорами архитектур AMD K7 и
Intel NetBurst.
Слайд 5Архитектура процессоров AMD K8
Отличия ядра Athlon 64 от современных Athlon
XP
Архитектура х86-64
Регистры
Адресация
Вычисления
Совместимость
Ядро процессора

Слайд 6Отличия ядра Athlon 64 от современных Athlon XP
Athlon 64 имеет
улучшенные алгоритмы предсказания ветвлений и увеличенный объем TLB, что позволяет
несколько увеличить производительность Athlon 64 по сравнению с Athlon XP на одинаковых тактовых частотах.Целочисленный конвейер Athlon 64 слегка удлинен для достижения более высоких тактовых частот. Так, целочисленный конвейер этого процессора имеет 12 стадий, а конвейер FPU – 17 стадий против 10 и 17 соответственно у Athlon XP.
В Athlon 64 появилась поддержка набора инструкций SSE2. Таким образом, процессор этот будет поддерживать все существующие расширения к системе команд x86, что позволит ему быстрее работать с приложениями, оптимизированными для процессоров Intel Pentium 4.
Athlon 64 имеет встроенный контроллер DDR SDRAM, что позволяет ему напрямую обращаться с памятью, значительно сокращая латентности при запросе данных.
В качестве шины, соединяющей процессор и чипсет материнской платы, в Athlon 64 используется шина HyperTransport, имеющая пропускную способность до 3.2 Гбайт в секунду в каждую сторону.
Процессором Athlon 64 поддерживается технология x86-64, позволяющая выполнение специальных 64-битных приложений.

Слайд 7Архитектура х86-64
Вот уже достаточно долгое время архитектура х86 не претерпевала
никаких принципиальных изменений
— не считать же, в самом деле,
принципиальным «подклеивание» новых наборов команд, впервыеосуществленное Intel в Pentium MMX. Собственно, ключевые особенности адресации команд,
сегментации памяти, сами х86 команды не менялись со времен i386 — это был последний
революционный процессор.
По-видимому, настало время перемен — и на сей раз знамя «революционной борьбы» решила
поднять AMD. Для этого она сделала решительный шаг.
Впервые со времен i386 архитектура х86 подвергается расширению — подчеркиваем, не
«подклеиванию» новых наборов команд, а полноценному расширению. Дело здесь даже не в том, что
теперь на каждом рабочем столе может стоять 64-битовый компьютер — само по себе это не
прибавляет производительности. Да и не так уж много у обычного потребителя задач, в которых это
важно (разве что криптография, поскольку при переходе на 64 битовые вычисления она выигрывает
едва ли не больше всех ).
Дело в том, что теперь архитектуре х86 (обновленной) вновь есть, куда
расти. Кроме того, данная архитектура исправляет некоторые огрехи, присущие х86 от рождения —
например, в 64 битном режиме применяется «плоская» модель памяти, количество регистров общего
назначения расширено до 16.

Слайд 8Архитектура х86-64
Самое время задаться вопросом — а кто же
выиграет от подобного расширения архитектуры? Для начала перечислим группы пользователей,
которым 64 адресация и 64 битовые вычисления нужны уже сейчас:пользователи CAD, систем проектирования, симуляторов уже давно нуждаются в объеме оперативной памяти больше 4 гигабайт. Хотя способы обходить это ограничение известны (к примеру, Intel PAE), за эти способы приходится расплачиваться производительностью. Действительно, процессоры Xeon поддерживают режим 36 битной адресации, в которой могут адресовать до 64GB оперативной памяти. Суть этой поддержки вкратце состоит в том, что оперативная память разбита на сегменты — и адрес состоит из номера сегмента и адреса ячейки внутри сегмента. Этот способ приводит к потере минимум 30% производительности при операциях с памятью. Да и программирование для «плоской» модели памяти в 64 разрядном адресном пространстве значительно проще и удобнее — благодаря большому адресному пространству ячейка имеет простой адрес, обрабатываемый за один раз. Не зря многие конструкторские бюро используют достаточно дорогие рабочие станции на RISC процессорах — там поддержка 64 битной адресации и большого объема памяти реализована давно.
в подобной же ситуации находятся пользователи баз данных. Любое крупное предприятие имеет немаленькую базу данных, и расширение максимального объема памяти плюс возможность адресовать данные в базе данных напрямую для них дорогого стоят. Как уже говорилось выше, хотя в специальных режимах 32 битная архитектура IA32 и может адресовать до 64GB памяти — но переход на «плоскую» модель памяти в 64 битном пространстве гораздо выгоднее. Переход на 64 битовую адресацию выгоден и с точки зрения скорости, и с точки зрения удобства программирования.

Слайд 9Архитектура х86-64
научные вычисления. Здесь ценен объем памяти, «плоская» модель
памяти, и отсутствие ограничений на размер обрабатываемых данных. Кроме того,
некоторые алгоритмы в 64 битном представлении имеют значительно более простой вид.есть область, которая очень выигрывает от 64 битных целочисленных вычислений. Это криптография и приложения, созданные для обеспечения безопасности. В этой области применение х86-64 способно привести если не к революции, то к огромному рывку вперед.
Таким образом, некоторый круг потенциальных потребителей новой архитектуры сложился уже сейчас. Тем же из покупателей, которым эти возможности не нужны, нет нужды использовать их в данный момент — для 32 битовых приложений ничего не меняется. Вообще ничего. Кроме того, вполне можно пользоваться 32 битными приложениями в 64 битной операционной системе — эдакие 64 бита «в рассрочку».

Слайд 10Регистры
В AMD64 к имеющимся регистрам было
добавлено несколько новых регистров,
а
существующие - расширены. Наиболее
кардинальные изменения произошли в
регистрах
общего назначения (РОН),регистрах SSE и регистре указателя
инструкций. Все они, за исключением
регистров SSE, стали 64-битными. Прежние
32-битные РОНы теперь входят в состав
новых 64-битных РОНов в качестве
младших частей. Кроме того, добавлено
еще 8, действительно новых, регистров
общего назначения R8-R15, аналогов
которых в x86-процессорах просто не было.
Впервые за 25 лет существования
архитектуры было увеличено число РОНов,
и не просто так, а вдвое! Нововведение
сулит заметный рост производительности,
конечно, при условии использования
соответствующих компиляторов.

Слайд 11Регистры
Следующее по значимости расширение - увеличение
числа регистров SSE. К регистрам XMM0-XMM7, появившимся в 1999 году
в процессоре Pentium III, были добавлены новые регистры XMM8-XMM15. AMD показалось мало добавить поддержку SSE2. Она увеличила вдвое число регистров, и тем самым сделала свой SSE-блок потенциально более мощным, чем в процессоре Pentium 4! Ведь в нем по-прежнему только 8 регистров SSE (появление SSE2 означало появление новых инструкций, но не новых регистров). Фактически блок SSE2 в AMD64 представляет собой нечто большее, чем просто SSE2. Это уже своего рода "SSE2+", хотя корректнее было бы назвать его "SSE2 Double Register Set". Забавно, что AMD покусилась на родную "вотчину" Intel - расширения SSE, - перехватив пальму первенства в этой области. Но следует учесть, что мощность нового блока может раскрыться только в 64-битной системе при использовании 64-битных приложений. Поэтому не стоит делать скоропалительных выводов по результатам 32-битной версии "Сандры". Тем более, что синтетические тесты, по большому счету, обходятся всего 2-3 регистрами, тогда как реальные приложения могут использовать больше. Что касается регистра флагов, то расширен он пока с запасом на будущее: старшие 32 бит процессором не используются (всегда 0). Расширение регистра указателя инструкций потребовалось при переходе к 64-битной адресации. Новый регистр теперь называется RIP, и включает в качестве младшей своей части регистр EIP. Набор регистров математического сопроцессора x87 остался без изменений. Впрочем, AMD больше не рекомендует им пользоваться, советуя 64-битным программам целиком перейти на SSE2.
Слайд 12Адресация
Основная причина перехода
к 64-битной архитектуре состоит в том, чтобы дать программе больше
2 Гб памяти, т. е. преодолеть ограничение 32-битных систем (верхние 2 Гб адресов в Win32 зарезервированы для ядра и API-функций). Цены на память постоянно снижаются. Сегодня гигабайт стоит дешевле $200, а значит, например, установка 16 Гб памяти обойдется менее чем в $3200 (что для сервера вполне приемлемо). Как я уже говорил, в 32-битных операционных системах физическое адресное пространство ограничено объемом в 4 Гб, которое приходится, к тому же, делить между приложениями, библиотеками, и ядром системы. Реально Windows-приложениям доступно всего 2 Гб адресов (3 Гб в Windows 2000 Advanced Server при указании ключа /3GB в boot.ini, что, впрочем, накладывает некоторые ограничения). Потребности же многих приложений - баз данных, программ обработки растровой графики и видео, систем автоматизированного проектирования, скоро превысят этот лимит, т. к. оперируют все большими наборами данных.Процессоры Intel начиная с Pentium Pro могут иметь и более 4 Гб физической памяти, но только через механизм PAE (Physical Address Extension) - "расширение физического адреса". Как Linux так и Windows 2000 Advanced Server способны задействовать эту память (вплоть до 64 Гб - это предел PAE), но приложения, увы, по-прежнему ограничены двумя гигабайтами адресного пространства. Предоставить доступ к большему пространству можно, но лишь используя специальные механизмы вроде AWE (Address Windowing Extensions) - "расширение адреса методом окна". Программирование с помощью AWE трудно само по себе, а главное, производительность при случайном доступе к памяти оказывается заметно ниже, чем при использовании плоской модели адресации. К тому же память, выделенная через AWE, не поддается свопингу и не может быть использована другими процессами. Небольшое отступление: во времена DOS был такой стандарт памяти - EMS (Expanded Memory Specification).

Слайд 13Адресация
Оригинальный IBM PC/XT мог иметь до 1 Мб физической памяти,
EMS позволил ему иметь до 16 Мб, но не напрямую,
а в виде "окна" в памяти размером 64 Кб, и набора банков отображаемых по очереди в это окно. Достигалось это применением специального драйвера и карты с памятью, вставляемой в слот расширения. На переключение банков тратилось значительное число тактов процессора (что, впрочем, все равно быстрее свопа на диск), зато таким образом преодолевалось ограничение 20-битной адресации IBM PC/XT. Избавиться от этих неудобств можно перейдя на новую адресацию.Процессоры Athlon 64 и Opteron не полностью 64-битные. Да, для указателей в программах используются новые 64-битные регистры, но объем адресуемой памяти в 16 экзабайт (1048576 терабайт) 64-битной адресации показался AMD излишним (вполне справедливо). Поэтому нынешние процессоры используют 48-битную адресацию, и позволяют адресовать до 256 Тб виртуальной памяти. Старшие 16 бит 64-битного адреса пока не используются. Для задания физического адреса в адресной шине отведено и того меньше - 40 бит, что позволяет иметь до 1 Тб физической оперативной памяти. Однако сейчас трудно представить себе компьютер даже с подобным количеством памяти, тем более, что будущие версии процессоров AMD64 могут иметь и более широкую адресную шину.


Слайд 15Адресация
Видно, что трансляция адреса стала четырехуровневой (в Pentium она была
двухуровневой, в режиме PAE - трехуровневой). Для того чтобы компенсировать
столь сложную процедуру, процессоры Athlon 64/FX и Opteron оснащены улучшенным блоком TLB (Translation-Lookaside Buffer). Блок TLB, иначе называемый кэшем страничной трансляции, используется при каждом обращении к памяти. Если соответствующий логический адрес уже был однажды преобразован в физический и информация об этом сохранилась в кэше, то обращение к памяти происходит моментально, минуя обращения к громоздким таблицам трансляций. Кэш TLB, также как и общий кэш процессора, является двухуровневым. У Athlon 64 он составляет 40 записей для инструкций, 40 для данных (L1) и 512 общих записей (L2), против 24 и 40 (L1), и 256 (L2) у Athlon XP.Скорость компьютера сильно зависит от нагрузки, приходящейся на каналы памяти. В типичном x86-коде около половины объема приходится на адреса операндов и связанные с ними константы, следовательно, двукратное увеличение разрядности адреса должно привести к увеличению объема кода примерно в 1.5 раза. Что в свою очередь означало бы пропорциональное увеличение нагрузки на шину данных и снижение эффективности кэша. Не говоря уже о такой "мелочи" как больший размер новых EXE- и DLL-файлов, а следовательно и большее потребление оперативной памяти. Иначе говоря, переход Athlon'а в 64-битный режим мог бы сопровождаться заметным падением производительности, примерно таким, какой произойдет при переходе с Athlon'а на равночастотный Duron.

Слайд 16Адресация
Предвидя возникновение этой проблемы, инженеры добавили новый режим адресации относительно
64-битного указателя инструкций - RIP-relative addressing. Эффективный адрес в этом
случае получается суммированием 32-битного адреса операнда, который играет роль смещения, и регистра RIP. Еще в 60-х годах было подмечено, что адреса, используемые в командах перехода имеют закон распределения близкий к нормальному, с вершиной в команде перехода.Т. е. чем дальше адрес отстоит от текущего значения указателя инструкций, тем меньше вероятность его применения. Такой подход позволяет снизить разрядность адресов не только команд перехода, но и вообще всех команд использующих ModRM-адресацию. В те моменты, когда 32 бит все же не хватит, компилятор сформирует полный 64-битный адрес, после чего, по возможности, снова продолжит генерировать 32-битные адреса. Сам по себе этот режим адресации не нов, и так или иначе использовался в разных компьютерах (не x86), а с переходом x86 на новую адресацию он показал себя во всей красе, практически ликвидировав главный недостаток 64-битного кода - большой размер.

Слайд 17Вычисления
Операции над 64-битными числами ведутся в криптографических системах, в научных
и финансовых задачах. Например, алгоритмы шифрации SSL используют 64-битное целочисленное
умножение. Добиться этого одной инструкцией на 32-битной машине невозможно, а 64-битная архитектура иногда позволяет обойтись одной командой, как следствие - колоссальное снижение нагрузки вычислительных блоков процессора и размера кода (примерно в 10 раз). Наличие 64-битных регистров может ускорить алгоритмы побитовой обработки данных, например, кодирование Хаффмана, применяемое в MPEG-сжатии.Рассмотрим несколько примеров.
64-битное сложение в x86:
00000000 03 C3 add eax,ebx
00000002 13 D1 adc edx, ecx
64-битное сложение в AMD64:
00000000 48 03 C3 add rax, rbx
Второй вариант короче на один байт, хотя и требует дополнительного префикса (48h). К тому же он не стирает содержимое регистров ECX, EDX и гарантированно выполняется за 1 такт процессора.

Слайд 18Вычисления
Функция 64-битного умножения в x86:
x86_mul_64x64 proc near
push ebp
mov ebp,
esp
push ebx
push esi
push edi
mov esi,[ebp+8]
mov edi,[ebp+12]
mov ecx,[ebp+16]
push ebp
mov [tempESP], esp
mov
eax,[esi]mov edx,[edi]
mul edx
mov ebx,edx
mov [ecx],eax
xor esp,esp
xor ebp,ebp
mov eax,[esi+4]
mov edx,[edi]
mul edx
add ebx,eax
adc ebp,edx
adc esp,0
mov eax,[esi]
mov edx,[edx+4]
mul edx
add ebx,eax
adc ebp,edx
adc esp,0
mov [ecx+4],ebx
mov eax,[esi+4]
mov edx,[edi+4]
mul edx
add ebp,eax
adc esp,edx
mov [ecx+8],ebp
mov [ecx+12],esp
mov esp, [tempESP]
pop ebp
pop edi
pop esi
pop ebx
mov esp, ebp
pop ebp
ret
x86_mul_64x64 endp
![Вычисления Функция 64-битного умножения в x86: x86_mul_64x64 proc nearpush ebpmov ebp, esppush ebxpush esipush edimov esi,[ebp+8]mov edi,[ebp+12]mov](/img/thumbs/9905a1e352a9883ec04fc703aae3862e-800x.jpg "Архитектура AMD K8 процессоров AMD Athlon64, Athlon64FX и Opteron Вычисления Функция 64-битного умножения в x86: x86_mul_64x64 proc nearpush ebpmov ebp,")
Слайд 19Вычисления
Функция 64-битного умножения в AMD64:
amd64_mul_64x64 proc near
mov rax, [rcx]
mul
[rdx]
mov [r8], rax
mov [r8+8], rdx
ret
amd64_mul_64x64 endp
Во втором варианте инструкций меньше
в 9 раз! В пределе можно обойтись и вовсе одной командой mul r64, если, например, необходимые данные уже содержаться в регистрах процессора. При делении разница будет еще больше: для x86 придется писать функцию длиной в 60-80 ассемблерных строк (я не буду ее приводить, но поверьте мне на слово), а для AMD64 размер останется тем же. Кроме того, для AMD64 опять можно обойтись одной командой div r64.![Вычисления Функция 64-битного умножения в AMD64: amd64_mul_64x64 proc nearmov rax, [rcx]mul [rdx]mov [r8], raxmov [r8+8], rdxretamd64_mul_64x64 endp Во](/img/thumbs/d530e6013246dd14f12bb68e3865964c-800x.jpg "Архитектура AMD K8 процессоров AMD Athlon64, Athlon64FX и Opteron Вычисления Функция 64-битного умножения в AMD64: amd64_mul_64x64 proc nearmov rax, [rcx]mul")
Слайд 20Вычисления
Кстати, 64 бита - не предел. Бывают и большие числа.
Операции над ними могут потребоваться при моделировании ядерных взрывов, исследовании
генома человека, к тому же они представляют чисто научный интерес. По данным AMD, для умножения двух 1024-битных чисел нужны следующие действия:
Слайд 21Вычисления
Очевидно четырехкратное преимущество последних. Кстати Athlon 64 выполняет сложение и
вычитание 64-битных чисел также быстро, как и 32-битных, а задержка
при чтении их из памяти лишь немногим выше чем у 32-битных и с лихвой компенсируется меньшим размером кода.До недавнего времени, поддержка 64-битной математики была только в высокопроизводительных серверах и дорогих рабочих станциях. Стоимость таких серверов на базе RISC-процессоров начиналась где-то с отметки в $25.000, а систем на базе Intel IA-64 от $10.000. Вот почему 64-битные сервера до сих пор составляли не более 5% всех серверов проданных на рынке. С приходом AMD64 ситуация может измениться - новые процессоры гораздо дешевле, но что еще важнее, они используют стандартные корпуса и комплектующие. Иначе говоря, с приходом Athlon 64/FX и Opteron 64-битные вычисления, наконец-то, могут пойти "в массы".

Слайд 22Совместимость
Главный фактор, объясняющий удивительный успех архитектуры x86 - все поколения
аппаратных средств сохраняли обратную совместимость с предыдущими. Это позволяло не
спешить с "апгрейдом" и переходить к новым программам постепенно. Когда-то 386-й (1985) стал первым 32-битным x86-процессором. Но полной поддержки со стороны операционных систем не было в течение восьми лет, пока в 1993 не вышла Windows NT 3.1. По настоящему же массовой 32-битная архитектура стала после выхода Windows 95, т. е. спустя десять (!) лет. Поэтому поддержка 16-битного режима была очень важна для 386-го, иначе бы он не прижился на рынке. Кстати, главным козырем Windows 95 на тот момент была именно аппаратная поддержка программ MS-DOS и 16-битных Windows-программ, позволяя им работать на полной скорости вместе с 32-битными программами. AMD64 исповедует тот же принцип перехода к новым системам и приложениям.AMD64 поддерживает работу как старых, 32-битных, так и новых, 64-битных, приложений, сосуществующих под 64-битной операционной системой. Причем, 32-битные приложения работают на полной скорости исполняясь аппаратными средствами, без эмуляции (в отличии от IA-64 архитектуры). Кроме того, процессор полностью совместим со старыми системами. Можно купить 64-битный компьютер и поставить на него 32-битную Windows 98/XP или даже Windows 3.1, используя его как быстрый Pentium, сохранив все старые приложениях и операционные системы. Позднее можно мигрировать на новую ОС с поддержкой 64-битных приложений и воспользоваться всеми преимуществами архитектуры.
Для реализации совместимости старых приложений с новыми AMD64 предлагает 2 режима: Long Mode ("длинный" режим) и Legacy Mode (унаследованный режим). В свою очередь, Long Mode состоит из 2 подрежимов: 64-bit Mode и Compatibility Mode. В 64-bit Mode раскрывается весь потенциал архитектуры: доступны новые регистры и 64-битное адресное пространство. Но приложение и сопутствующие dll-ки должны быть откомпилированы заново. Режим Compatibility Mode существуют для запуска старых 32-битных приложений из под новой 64-битной операционной системы. Для этих приложений все выглядит так, как если бы они работали на обычном x86-процессоре. Ну и Legacy Mode это не что иное, как старые-добрые режимы работы x86 (Protected Mode, Virtual 8086 Mode, Real Mode). Именно в Legacy Mode работают 32-битные Windows 9X/ME/NT/2K/XP.


Слайд 24Совместимость
Большинство 64-битных операционных систем будут поддерживать Compatibility Mode. Но вызов
системной функции, сделанный в 64-битной среде 32-битным приложением, нуждается в
преобразовании некоторых аргументов, в основном, указателей адреса. "Прослойка", выполняющая на лету подобные преобразования, является важной частью системы. Windows реализует ее через подсистему "Windows on Windows". Специальная библиотека, wow.dll, динамически подключается ко всем 32-битным приложениям и выполняет следующие функции:1. Приводит аргументы к 64-битному виду
2. Передает управление (вызов) 64-битному ядру
3. Приводит результаты вызова обратно к 32-битному виду
4. Возвращает их приложению


Слайд 26Совместимость
Преобразования не столь накладны, как кажутся, большинство из них сводятся
к добавлению нулей к аргументам функции и к их последующему
удалению. К счастью, системные вызовы случаются все же не так часто, весь остальной код работает без посредников. Кроме того, это небольшое отставание может частично компенсироваться ростом скорости самой операционной системы, т. е. системных библиотек и драйверов, за счет использования новых регистров.Способность выполнять одновременно 32-битные и 64-битные приложения особенно ценна для программистов. При разработке 64-битных приложений, они могут пользоваться 32-битным инструментарием на той же машине, на которой отлаживают 64-битный код. Все могут пользоваться своими любимыми редакторами, которые в настоящее время являются 32-битными и возможно никогда не будут перенесены на 64-разрядную ОС. 32-разрядная совместимость делает возможным для программистов разрабатывать и проверить их код на той же самой машине без перезагрузки.
Чтобы продемонстрировать полную совместимость своего детища, AMD проверила системы на новом процессоре в более чем 50 (!) операционных системах. Вот некоторые примеры систем, совместимость с которыми проверена:
Windows (3.1, 9x, Me, 2000 Pro, 2000 Server, 2000 Advanced Server, WfW, XP)
Windows NT (3.51 WS, server, 4.0 w/SP6, NT 4 Workstations)
DOS (MSDOS 6.21, Novell DOS 7.0, PC DOS 6.1, 6.3, 7.0
Linux (Mandrake 7.0, 7.1, Redhat 6.0, 6.1, 6.20, 7.0, Slackware 1.2, 2.0, SuSE 7.0)
Unix (SCO, FreeBSD 3.0, Solaris 2.5, 2.6, 7, 8)
Misc (OS/2 Warp3.0, 4.0, BeOS 4.5, 5.0, Netware 4.11, 4.2, 5.0, 5.1)

Слайд 27Ядро процессора
Блок-схема
Кэш инструкций - I-cache
Кэш данных - D-cache
Буфер быстрого
преобразования адреса – TLB
Кэш память второго уровня - L2 cache
Блок предсказания переходов – BTB
Декодер
Контроллер памяти
Контроллер Hyper Transport


Слайд 29Кэш инструкций - I-cache
Его размер остался таким же, как и
в Athlon — 64КВ. Он так и остался 2-х канальным
частично-ассоциативным — таким образом, особых изменений по сравнению с Athlon в этом параметре нет. Размер блока — 64 байта. Наличествуют два набора тэгов — fetch port (порт выборки) и snoop (слежения). Содержимое защищено при помощи проверки четности.
Слайд 30Кэш данных - D-cache
D-cache, он же кэш данных, также
2-х канальный частично-ассоциативный. В текущей модификации поддерживается 40-битовый физический и
48-битовый линейный адрес — впрочем, при необходимости этот параметр можно увеличить. Размер блока данных также 64 байта. Из нововведений — MOESI протокол работы кэша первого уровня, ранее использовавшийся в чипсете AMD760MP(X). Поддерживает две 64-битовых операции чтения/записи каждый такт в различные банки! Три набора тэгов — port A, port B, snoop. Задержка выборки из этого кэша — 3 такта при выровненных обращениях, и плюс 1 такт, если данные не выровнены. Кстати, это достаточно низкое пенальти за то, что данные не выровнены — в Pentium 4, насколько известно автору, это пенальти значительно больше — по измерениям различных тестеров, цифры получаются от 6 до 10 тактов, в зависимости от методики. Сама Intel хранит гордое молчание на сей счет. Поддерживается hardware prefetch (блок предвыборки). Все данные защищены ECC.
Слайд 31Буфер быстрого преобразования адреса – TLB
Translation Lookaside Buffer — буфер
быстрого преобразования адреса, представляющий собой специальную кэш-память; используется для ускорения
страничного преобразования.L1 TLB полностью ассоциативные, и поддерживают как 4К, так и 2М/4М страницы. Это должно особенно порадовать любителей «как следует посчитать» — в научных расчетах частенько используются страницы большого размера. Ёмкость TLB для стандартных 4К страниц - 32 входа, а для 2М/4М — 8 входов.
В отличие от TLB для L1 cache, L2 TLB поддерживает только 4К страницы — но зато емкость уже 512 входов с 4-х канальной ассоциативностью.

Слайд 32Кэш память второго уровня - L2 cache
L2 cache, как
и следовало ожидать, эксклюзивен по отношению к L1. Сохранена
16-канальная
частично-ассоциативная организация — по-видимому, AMD сочла бессмысленным дальнейшее увеличение этого параметра.В архитектуре К8 AMD модернизировала шину L1-L2 cache. Теперь вместо одной двунаправленной шины шириной 64 bit мы получили две встречных шины по 64 бита (64 + 64), что сильно снижает вероятность возникновения «затора» в этом месте. Кстати, это не замедлило сказаться на низкоуровневых тестах — скорость кэша второго уровня выросла как минимум на четверть при тех же частотах. Не менее важно то, что теперь снижены (собственно, практически полностью нивелированы) отрицательные эффекты от «перегруза» шины L1-L2.
Кроме того, L2 cache содержит предварительно декодированные инструкции и branch prediction bits (своего рода указатели, или просто «флаги» предсказания ветвления). Все это вместе составляет некоторый уникальный (по словам AMD) механизм, увеличивающий производительность процессора.
Интересно, что фактически декодирование (вернее, подготовка к нему) начинается прямо в L2 cache. Это означает, что при «выселении» данных из I-кэша эта информация перемещается в L2 cache, где для нее зарезервировано место. При этом повторно используются ECC биты для быстрой очистки/совместного использования страниц кэша.

Слайд 33Блок предсказания переходов – BTB
(Branch Target Buffer)
Блок предсказания переходов —
он подвергся значительной переработке. Теперь он для увеличения точности ведет
историю 16К (между прочим, это в 4 раза больше, нежели у Athlon XP) переходов, и также помнит 2К адресов назначения. Все это, вместе с 12-входовым стеком возврата адреса, позволяет AMD заявить о 5%—10% преимуществе в точности предсказаний по сравнению с предыдущим поколением процессоров. Это тем более важно, что из-за слегка удлинившегося конвейера (12 стадий вместо 10) процессор стал чуть более чувствителен к промахам предсказания переходов — правда, из-за значительно снизившейся задержки доступа в память пенальти в производительности, скорее всего, будет даже меньше, нежели у Athlon XP. Кстати, тут же надо указать, что улучшен и механизм prefetch — теперь программный prefetch не отключается при заполнении буферов, а аппаратный лучше работает в содружестве с программным. Блок предсказания переходов —")
Слайд 34Декодер
Декодер подвергся наибольшей переработке. Собственно, своим удлинением конвейер обязан именно
декодеру — именно там добавились две дополнительные стадии.
Декодер превращает
нерегулярные команды х86 (к тому же переменной длины) в µOPs (микрооперации) фиксированной длины. Причем за один такт каждый декодер может обработать инструкцию длиной до 16 байт (!) и отправить планировщику на исполнение µOPs, которые затем будут упакованы в группы по трое. При этом инструкции могут быть превращены в µOPs двумя разными путями. 1. При помощи блока Fastpath (быстрой обработки) инструкция х86 превращается в 1 или 2 µOPs, каковые затем (упакованные в блоки по три µOPs) направляются в планировщик.
2. при помощи Microcode decoder инструкции х86 превращаются в последовательность из более чем двух µOPs (для сложных операций) каждая, при этом готовые последовательности загружаются из ROM (точнее сказать, из MIS — Microcode Instruction Sequencer, подобие ПЗУ, содержащее набор заранее запрограммированных последовательностей микроопераций). При этом в отличие от Athlon XP, заметно больше инструкций х86 используют более быстрый Fastpath декодер, имеющий меньшие задержки в тактах — 2 против 5.
Кроме того, подобное устройство декодера приводит еще к нескольким следствиям:
SSE инструкции в AthlonXP переводятся в µOPs при помощи Microcode decoder, а в Athlon64 — при помощи Fastpath decoder. Соответственно, мы вправе ожидать небольшого прироста производительности в данном наборе команд даже при прочих равных условиях.
Также известны следующие данные:
Athlon64 исполняет на 8% меньше микроопераций в наборе SPECint 2000.
Athlon64 исполняет на 28% (!!!) меньше микроопераций в SPECfp 2000.
Здесь надо пояснить, что в данном случае не производительность процессора стала хуже, а просто изменение методики разбиения команд х86 на µOps привело к уменьшению общего количества µOPs, в которые превращается программа.
Теперь становится понятно, почему AMD изменяла прежде всего именно декодер — можно бороться за то, чтобы исполнять как можно больше работы за такт. А можно подумать и сделать так, чтобы было меньше работы вообще.

Слайд 35Контроллер памяти
Интегрированный контроллер памяти — это одна из «визитных карточек»
микроархитектуры К8. По крайней мере, именно эта черта беспрестанно подчеркивалась
в маркетинговых документах AMD, когда речь заходила о микроархитектуре К8.Как известно, скорость работы с памятью зависит от ширины шины данных, частотой синхронизации, задержками доступа к ячейкам памяти. Если первое от AMD мало зависит (скорее от производителей ОЗУ и материнских плат), более того, она должна асинхронизировать шину, остается только один выход — уменьшить задержки. Этого им удалось добиться, результаты очень впечатляют: минимальная задержка с памятью DDR 400 составляет 65 тактов, против 189 у Pentium4.
Теперь можно понять, что цифры задержек для Athlon 64 и Opteron не просто хороши! Они великолепны! А с ростом частоты процессора станут еще лучше. Надо отдать AMD должное — подобным ходом (интеграцией контроллера в процессор, и, как следствие, малыми задержками доступа) AMD сильно облегчила себе работу во всех ситуациях, связанных со случайным доступом в память — вернее, снизятся не задержки доступа к ячейке памяти (они зависят только от характеристик самой памяти и топологии системы), снизится общее время реакции подсистемы памяти. А вот случайный доступ к различным ячейкам частенько, например, встречается в базах данных. И здесь разница между «традиционными» чипсетами и конструкцией AMD будет, по-видимому, уже не на проценты, а в разы. Браво, AMD!

Слайд 36Контроллер Hyper Transport
HyperTransport является протоколом последовательной шины "точка-точка", которую AMD
использует для подключения многих элементов: от контроллеров ввода/вывода до мостов
AGP/PCI и даже центральных процессоров. Это достаточно важная часть системы — и тем более важная, что именно в этой области есть достаточное количество нововведений, ранее в архитектуре х86 не употреблявшихся.AMD улучшила свою разработку под именем Hyper Transport, приписав ей порядковый номер 2.0. Скорость передачи данных по ней составляет 6.4 Гб/с, но это не предел, есть и более, зато уникальность ее в том, что минимальная задержка подсистем ввода/вывода — 50 нс.
Интересные данные можно предоставить о задержках во время работы подсистемы ввода/вывода, и их зависимости от нагрузки. Видно, что только случай максимальной загрузки и процессора, и подсистемы ввода/вывода способен серьезно увеличить задержки, но задержка доступа в 250 наносекунд выглядит серьезной только на фоне задержки в 50 наносекунд. По сравнению же со всеми остальными традиционными подсистемами ввода/вывода все очень хорошо.

Слайд 37Контроллер Hyper Transport
Кроме того, раз уж мы заговорили о шине
Hyper Transport, позволим себе напомнить уровень ее масштабируемости. Для этого
приведем следующую диаграмму:Диапазон скоростей, доступных для Hyper Transport, впечатляет. Вообще говоря, даже сама по себе эта шина — весьма сильная разработка. В ней достаточно хорошо сочетаются простота разводки, великолепные скоростные качества, низкие задержки, хорошая масштабируемость — и при всем при этом совместимость с давно изученной программной моделью PCI, что немаловажно для беспроблемного внедрения ее в промышленность.

Слайд 38Контроллер Hyper Transport
Хочется также продемонстрировать, насколько разводка Hyper Transport проще,
нежели разводка традиционных шин: →
Легко заметить, какую площадь на печатной
плате занимает шина AGP 8x с пропускной способностью 2 ГБ/секунду, а какую — шина Hyper Transport, прокачивающая до 6.4 ГБ/секунду. 
Слайд 39 Конструктивное исполнение процессоров AMD K8
На данный момент процессоры семейства
AMD K8 представлены на рынке в трех основных конструктивах:
Socket 754
Socket
940Socket 939

Слайд 40Socket 754
Этот разъем предназначен для установки Athlon64 c одноканальным контроллером
памяти и шиной Hyper Transport, работающей на частоте 800 МГц.
В последнее время в этом же конструктиве предлагается процессор
AMD Sempron, отличающийся от Athlon’а уменьшенным до 256КВ кэшем второго уровня и отсутствием поддержки набора команд х86-64.

Слайд 41Socket 940
В отличие от S754 этот разъем поддерживает процессоры AMD
Opteron – серверного представителя архитектуры AMD K8.
Помимо двухканального контроллера памяти
этот конструктив предполагает работу с регистровыми небуфферезироваными модулями ОЗУ, поддерживающими ECC ( Error Checking & Correcting).Изначально для S940 имелась возможность установки процессоров AMD Athlon64FX, представляющих по сути тот же Opteron, но лишенный поддержки многопроцессорности, но взамен получивший свободный множитель – подарок оверклокерам.

Слайд 42Socket 939
1 июня 2004г. AMD анонсировала новую платформу Socket 939,
которая должна уместить в себя все процессоры AMD64.
AMD Socket 939
практически не отличается от предшествующих сокетов - и с ним по-прежнему легко работать. К тому же, у производителей материнских плат скопился немалый опыт внедрения Socket 940, который аналогичен по дизайну. Возможность использования прежнего дизайна облегчает выход производителей материнских плат на рынок Athlon 64. Напомним, что Socket 939 поддерживает как новый Athlon 64 FX, так и новые версии Athlon 64. AMD желает сделать Socket 939 новым стандартом. Socket 940, в той или иной мере, вытесняется, за исключением решений на Opteron. Socket 754 с одноканальным контроллером памяти остаётся на рынке, однако он плавно переходит в стадию дешёвых решений.
Техническое различие между Socket 940 и 939 невелико – отсутствие одного контакта обуславливает невозможность работы в многопроцессорных системах, но также имеются еще некоторые различия в разводке с т.з. расположения контактов для предотвращения установки нывых процессоров S939 в старые материнские платы S940.
Платформа на Socket 939 также поддерживает работу шины HyperTransport на частоте 1 ГГц, используя при этом передачу DDR, в отличие от принятой раньше частоты 800 МГц. В результате суммарная (двунаправленная) пропускная способность составляет 8 Гбайт/с, а не прежние 6,4 Гбайт/с.

Слайд 43Socket 939
Для большей наглядности приведем изображения процессоров разных конструктивов: вверху
– S754 и S939
внизу – S939 и S940.

Слайд 45AMD 8000
Давно известно, что часто именно чипсет, как ближайшее окружение
процессора, создает впечатление о производительности системы и ее преимуществах/недостатках. Так
что вполне понятен интерес к тому, на каком же чипсете будут работать системы на Athlon 64 и Opteron.Надо сказать, что и здесь AMD сумела найти нестандартный подход. Еще при объявлении компанией шины Hyper Transport было вполне логично предположить, что именно эта шина будет рано или поздно использоваться в новых системах на базе их очередного процессора. Но то, что предложила компания, выходит за рамки обычного чипсета — да и за рамки «необычного» чипсета выходит тоже.
Классический чипсет состоит, как правило, из двух (реже одной или трех) микросхем, в которых одна, содержащая контроллер памяти, AGP, и какую-либо вспомогательную шину (PCI либо любую другую) между микросхемами чипсета, обычно называется Northbridge. Соответственно, всевозможные контроллеры ввода/вывода, а в последнее время, как правило, и контроллер шины PCI, интегрируются в, так называемый, Southbridge. Так устроено подавляющее большинство чипсетов. Повторим — Northbridge и Southbridge соединяются той или иной шиной. Это может быть PCI, как в чипсетах ALi или старых чипсетах VIA, это может быть PCI64 «разных мастей», как в некоторых чипсетах Server Works или AMD760MP(X), это могут быть собственные шины, как в чипсетах SiS, Intel, или новых чипсетах VIA. В конце концов, это может быть Hyper Transport, как в чипсетах от NVIDIA.
AMD выбрала Hyper Transport. Во-первых, потому что это шина ее собственной разработки. Во-вторых, потому что она имеет наибольшую скорость на сегодняшний момент из доступных на рынке шин. В-третьих, потому что ее разводка проста и позволяет создать недорогие материнские платы, что немаловажно при выборе платформы. Так что причины выбора вполне понятны. Но AMD пошла дальше, гораздо дальше.

Слайд 46AMD 8000
Ведь что осталось из функций чипсета? Контроллер памяти —
в процессоре. AGP — частично там же. Контроллер шины Hyper
Transport — и тот в процессоре. Остается часть AGP, контроллеры ввода/вывода, контроллер PCI… Собственно, все. Можно, конечно, все оставшиеся части интегрировать в одну микросхему (NVIDIA так и сделала). Но AMD нашла еще более красивое решение. Было создано три микросхемы (под объединяющей их серией AMD8000):AMD8151, Hyper Transport — AGP tunnel
AMD8131, Hyper Transport — PCI-X контроллер

Слайд 47AMD 8000
AMD8111, Hyper
Transport — контроллер ввода/вывода, контроллер
шины PCI, BIOS.Зачем три микросхемы, когда в принципе можно обойтись одной? А дело здесь вот в чем — редкому пользователю нужны абсолютно все возможности, предоставляемые чипсетом. Обычно часть функций не используется, но пользователь все равно за них платит — и, в общем-то, все привыкли к тому, что это нормальное положение вещей. Но скажите, многим ли дома или в офисе нужен контроллер шины PCI-X, которая применяется отнюдь не в домашних машинах? А ведь добавление подобной шины ощутимо увеличивает цену конечной системы. В то же время вообще отказаться от этой шины нельзя, она активно используется в серверах. А многим ли серверам вообще нужно AGP? Да, по привычке мы ставим туда AGP видеокарту — но просто потому, что процесс перехода на AGP шину произошел слишком удачно, до практически полного исчезновения PCI видеокарт. Так вот, теперь не надо платить за ненужные вам функции — для построения системы обязательна только одна микросхема — AMD8111. Остальные две, вообще-то, могут отсутствовать. Конечно, нынешнюю машину без AGP разъема трудно себе представить — но, говоря откровенно, есть огромная область работ, в которой вполне справляется и интегрированное видео, а удешевление и уменьшение габаритов системы весьма желательны. Домашние, игровые компьютеры вполне разумно строить на комплекте AMD8151 + AMD8111 — есть все, что необходимо, и нет лишних функций. Сервер — извольте, рекомендуем AMD8131 + AMD8111.

Слайд 48AMD 8000
Вместо одного чипсета для мейнстрим продуктов, одного для рабочих
станций, одного или нескольких для серверов — мы получили один
строительный набор из трех компонент, которые можно объединять практически в любой удобной для нас комбинации. Неожиданная, но интересная и здравая идея — не говоря уже о том, что она сильно сэкономит силы AMD в процессе технической поддержки. Ведь одно дело поддерживать один продукт, хоть и трехкомпонентный, а другое — десяток различных чипсетов. Так что и в этой области решение интересное и эффективное.
Слайд 49
ATI Radeon Xpress 200/P
Нельзя не признать, что на этот раз у
ATI получился действительно инновационный чипсет — все прошлые поколения (IGP 320/340, IGP 9000/9100/Pro) были лишь более или менее добротными повторениями уже существующих на рынке решений, исключая, разумеется, фирменную встроенную графику канадцев. Здесь же внедрение PCI Express традиционно выливается в наличие графического слота PCIEx16, но вот четыре периферийных порта PCIEx1 соединены не с южным, а с северным мостом. Решение вполне логичное: поскольку контроллер памяти все равно интегрирован в процессор, а в его отсутствие северный мост выглядит «пустым». К тому же теперь высокоскоростной PCIE-периферии открыт более короткий путь и, следовательно, более быстрый доступ к памяти. Разумеется, этот мост чипсета соединяется также с процессором (потенциально любые модели архитектуры AMD64) по шине HT с частотой до 1 ГГц и с южным мостом по шине PCI Express (параметры этого интерфейса в документации не указаны). HT частотой 1 ГГц — это, конечно, всего лишь красивые цифры для победных пресс-релизов, в реальности такая пропускная способность шины приложениям не нужна. Для связи с южным мостом чипсеты ATI всегда использовали стандартные интерфейсы (PCI, позже HT, теперь вот выбор сделан в пользу очередной новинки) — это просто в реализации и позволяет использовать южные мосты от других производителей (мы видели такое предложение от ULi).Чипсеты Xpress 200 (кодовое название RS480) и Xpress 200P (кодовое название RX480) отличаются наличием встроенной графики у первого. Заметим, что протестированная нами плата на Xpress 200 — первый реальный интегрированный продукт под новую платформу AMD, хотя вообще-то интегрированные чипсеты под K8 были анонсированы как бы не раньше самих процессоров. Но то ли включение встроенного видео заметно тормозило систему в обычных приложениях (а ожидать от VIA или SiS чипсета с пристойной производительностью в 3D вообще нет оснований), то ли по еще каким-то причинам — рабочие платы рынок так и не заполонили. По заявленным характеристикам, видеоускоритель в Xpress 200 — аналог Radeon X300, но точные параметры (вроде частоты работы ядра) не сообщаются. Напомним, что X300 — это вариант Radeon 9600 под PCI Express, обладающий аппаратной поддержкой DirectX 9 (вершинные и пиксельные шейдеры версии 2.0)

Слайд 50
ATI Radeon Xpress 200/P
На предлагаемой блок-схеме новых
чипсетов перечислены их ключевые характеристики:

Слайд 51
ATI Radeon Xpress 200/P
Интересной особенностью RS480 является фирменная технология HyperMemory.
Традиционно интегрированное видео использует под кадровый буфер выделенную область системной памяти. Плюс такого подхода очевиден — путем незначительного (как правило) снижения доступного объема общей памяти достигается полная работоспособность встроенной графики без возни с разводкой и распайкой на материнской плате дополнительных микросхем. Однако недостатком такого режима (он называется UMA — Unified Memory Architecture) является снижение общей производительности — контроллеру памяти приходится чередовать «важные» обращения процессора и «дежурные» (простое обновление экрана монитора) — видеочипа. ATI предлагает в этой ситуации интегрировать на плату выделенную память, которая будет использоваться именно под буфер кадров. Конкретных вариантов реализации предусмотрено много (например, размер буфера может быть до 128 МБ); мы подождем серийных изделий, чтобы понаблюдать за тенденциями. В нашем инженерном образце материнской платы на Xpress 200 был применен, похоже, минимальный вариант: микросхема GDDR объемом 16 МБ со временем выборки 2,5 нс от Samsung. Впрочем, даже при наличии выделенной памяти предусмотрена и работа в режиме UMA .
Слайд 52
ATI Radeon Xpress 200/P
Из дополнительных особенностей интегрированного видео RS480 отметим
поддержку вывода изображения на два независимых приемника: CRT/LCD или TV/LCD (в сочетании с внешней графической картой ATI поддерживается вывод на 3 монитора). Очень вероятно, что стандартным элементом задней панели серийных плат на Xpress 200 станут разъемы D-Sub (аналоговый вывод) и DVI (цифровой), как на нашем инженерном образце.Южные мосты — слабейшее место предыдущих поколений чипсетов ATI, именно их функциональность вызывала наибольшие нарекания своей скудностью. На этот раз (официальной парой Xpress 200/P является IXP400) все куда лучше. Итак, поддерживаются:
до 7 слотов PCI (все слоты PCI Express соединены напрямую с северным мостом);
до 4 устройств SATA с возможностью организации двух независимых RAID-массивов уровней 0 и 1 (на самом деле в чипсет просто интегрированы два независимых двухпортовых RAID-контролера от Silicon Image; почему не один четырехпортовый, с функцией RAID 0+1 — науке это не известно, вряд ли обошлось бы сильно дороже);
до 4 устройств (2 канала) ATA133;
до 8 устройств USB 2.0;
AC'97-аудио (5.1 или 7.1) и MC'97-модем;
обвязка для низкоскоростной и устаревшей периферии.
Все на уровне, отсутствуют лишь High Definition Audio (уже пора бы, но обещают только в IXP450(500?)) и интегрированная сеть. ATI полагает, что с появлением PCI Express и большого количества гигабитных сетевых адаптеров под этот интерфейс (от Marvell, Broadcom…) необходимость в интеграции MAC-контроллера в чипсет отпала, так как один полноценный внешний чип обойдется дешевле, а работать будет не медленнее.

Слайд 53VIA K8T890
На рынке чипсетов под AMD64 довольно долго царило затишье. Выход
на «рынок вообще» технологии PCI Express и выход на рынок продуктов под AMD64 компании ATI с чипсетами Xpress 200/P неизбежно привел к покорению новых рубежей. Рассотрим первый ход известного производителя — компании VIA Technologies.На блок-схеме нового чипсета хорошо видно его отличие от предшественников: приход PCI Express выражается в наличии графического интерфейса PCIEx16 вместо AGP. Запланированные на ближайшее будущее северные мосты VIA поддерживают суммарно 20 линий PCI Express, и в данном (K8T890) случае остающиеся 4 линии предназначены для подключения слотов PCIEx1 для периферии. Не анонсированные пока дальнейшие продукты VIA будут позволять использовать эти четыре линии под второй графический слот, для создания систем с парой видеоадаптеров (по типу NVIDIA SLI или просто для мультимониторных решений). В случае же K8T890 нет другой возможности организовать поддержку PCIE-периферии, так как старый южный мост не имеет контроллера этой шины, да и видеокарты NVIDIA все равно бы не заработали в режиме SLI в материнской плате на базе этого чипсета (текущие видеодрайверы калифорнийской компании этого не позволяют).


Слайд 55VIA K8T890
Южному мосту VIA VT8237 на момент написания этой
статьи исполнилось уже полтора года, в течение которых он является бессменной парой для всех новых северных мостов компании. И если на момент анонса это был, пожалуй, самый функциональный продукт на рынке, то сейчас он ничем не выделяется среди конкурирующих решений. За прошедшее время VIA успела отказаться от выпуска VT8239, предпочтя ориентироваться сразу на VT8251, но последний все еще находится в стадии доводки, его массовое производство ожидается лишь во втором квартале 2005-го. Так что хотя при анонсе официальной парой для K8T890 назывался VT8251 (на сайте VIA до сих пор доступна соответствующая иллюстрация), придется, видимо, до выхода K8T890 Pro обходиться старыми резервами.Итак, функциональность VIA K8T890 выглядит следующим образом:
двунаправленная шина HyperTransport (частота работы 1 ГГц, ширина 16 бит в каждом направлении) до процессора (с интегрированным контроллером памяти);
графический интерфейс PCIEx16;
до 4 портов PCIEx1, подключаемых непосредственно к северному мосту;
связь с южным мостом по шине Ultra V-Link с избыточной пропускной способностью 1 ГБ/с;
до 6 слотов PCI;
до 2 портов Serial ATA на 2 устройства SATA150;
интерфейс еще для 2 портов Serial ATA (требуется внешний PHY-контроллер);
возможность организации RAID-массива уровней 0 и 1 (а также 0+1 в случае 4 портов) из SATA-дисков;
до 4 устройств (2 канала) ATA133;
до 8 устройств USB 2.0;
MAC-контроллер для сети 10/100 Мбит/с (Fast Ethernet)
AC'97-аудио (5.1) и MC'97-модем;
обвязка для низкоскоростной и устаревшей периферии.

Слайд 56VIA K8T890
Северный мост — на уровне, улучшать там просто нечего,
надо лишь иметь в виду, что поддержка PCI Express во всех существующих чипсетах автоматически означает наличие слота PCIEx16 и отсутствие слота AGP: гибридные решения пока не анонсированы. Частота и разрядность шины HT максимальны среди конкурентов. Южный мост никак нельзя назвать передовым, а многочисленные «вкусности» VT8251 (High Definition Audio, PCI Express для периферии, продвинутый RAID-контроллер, SATA II…) на подходе . Кстати, можно точно сказать, чего в VT8251 не будет: VIA (как и ATI) полагает, что интеграция MAC-контроллера гигабитной сети в чипсет экономически и функционально неоправданна, так как один полноценный (MAC+PHY) внешний чип обойдется дешевле, а работать (через порт PCI Express) будет не медленнее.
Слайд 57NVIDIA nForce 4
Прежде всего, отметим, что новое семейство чипсетов от NVIDIA
для платформы Athlon 64, nForce4, представляет собой дальнейшее развитие завоевавшего огромную популярность набора логики nForce3 Ultra. Главным нововведением, появившемся в наборах логики линейки nForce4, стала поддержка шины PCI Express. Однако помимо этого в nForce4 есть ещё несколько интересных сюрпризов, о которых будет сказано несколько ниже.Мы же пока сосредоточимся именно на поддержке в nForce4 шины PCI Express. Особенность реализации этой шины в новом чипсете от NVIDIA обуславливается архитектурой самого набора логики. Следует отметить, что подобно своему предшественнику, nForce4 является одночиповым решением. Благодаря тому, что контроллер памяти в Athlon 64 системах вынесен в CPU, NVIDIA смогла совместить функции северного и южного моста внутри одной микросхемы.
Результатом этого является в первую очередь отсутствие дополнительной шины, связующей мосты и ограничивающей скорость соединений между контроллерами северного и южного моста. То есть, взаимодействие контроллеров внутри чипсета у nForce4 организовано несколько эффективнее, чем в иных наборах логики, состоящих из двух микросхем.

Слайд 58NVIDIA nForce 4
Второе преимущество одночипового решения напрямую связано с тем, что
все линии (lane) PCI Express реализованы посредством одного контроллера. В конкурирующих решениях поддержка шин PCI Express x16 и PCI Express x1 возлагается на различные микросхемы. В nForce4 же за поддержку всех этих шин отвечает один контроллер. В итоге, чипсет nForce4 предоставляет большую гибкость в конфигурировании поддерживаемых им 20 линий PCI Express. Так, производители материнских плат теоретически могут отказаться от реализации PCI Express x1, объединив их в шину PCI Express x4, или же разделить шину PCI Express x16 на две PCI Express x8. Благодаря этому чипсет nForce4 может таить в себе немало сюрпризов, одним из которых является возможность поддержки более одной графической карты с интерфейсом PCI Express (режима SLI).Ещё одним нововведением, присутствующим в nForce4 и делающим этот чипсет одним из самых прогрессивных наборов логики на сегодняшний день, является контроллер жёстких дисков второго поколения. Среди плюсов этого контроллера следует отметить поддержку четырех каналов Parallel ATA и четырёх каналов Serial ATA одновременно, чего не может на сегодня ни один из конкурирующих продуктов. Однако это ещё не всё: nForce4 стал первым набором логики, практически полностью соответствующим спецификации Serial ATA II, то есть поддерживающим "горячую замену" жёстких дисков, NCQ и пропускную способность интерфейса до 3 Гбит в секунду. Таким образом, nForce4 к выходу жёстких дисков будущего поколения готов.
Что же касается поддержки RAID, то и в этой части nForce4 получил определённое развитие. В частности, этот чипсет поддерживает массивы уровня 0, 1 и 0+1, которые могут быть составлены из дисков с любыми интерфейсами, в том числе и Parallel ATA. Управление массивами из среды Windows выполняется путём использования специальной утилиты nvRAID.

Слайд 59NVIDIA nForce 4
Заметим также, что контроллер жёстких дисков nForce4 имеет своего рода
"двухканальную" архитектуру. То есть, этот контроллер связан с арбитром чипсета двумя независимыми шинами, что в ряде случаев позволяет нарастить пропускную способность и уменьшить латентности при работе процессора с массивами данных, располагаемых на жёстких дисках.Также NVIDIA вновь увеличила в своём наборе логики число портов USB 2.0. Теперь их стало десять против восьми у более ранних чипсетов.

Слайд 60NVIDIA nForce 4
Отдельно
следует упомянуть и сетевые возможности nForce4. наборы системной логики этого
семейства не просто имеют интегрированный гигабитный сетевой контроллер, но и снабжены встроенным средством сетевой защиты (Secure Networking Engine) NVIDIA ActiveArmor. к интегрированному в свои наборы логики гигабитному сетевому контроллеру компания NVIDIA поставляет достаточно продвинутую программу-брандмауэр - NVIDIA Firewall 2.0 для nForce4 является уже программно-аппаратным средством, возлагающим часть операций по фильтрации сетевых пакетов не на центральный процессор, а на встроенный в чипсет аппаратный движок ActiveArmor.
Слайд 61NVIDIA nForce 4
Фактически, в случае использования NVIDIA Firewall 2.0, на процессор возлагается
лишь нагрузка, связанная с подстройкой параметров аппаратного ActiveArmor. Вся же основная работа по обработке и сортировке сетевых пакетов возлагается на чипсет. В результате, NVIDIA Firewall 2.0, работая на чипсетах семейства nForce4, практически не нагружает процессор, в отличие от аналогичных программных брандмауэров сторонних производителей.На рисунке справа: обычный Firewall загружает CPU на 75%.
На рисунке слева: NVIDIA Firewall 2.0 использует аппаратный ActiveArmor, снижая нагрузку на CPU до 10%.

Слайд 62NVIDIA nForce 4
Что же касается поддержки процессоров, то NVIDIA nForce4 поддерживает
шину HyperTransport с частотой до 1 ГГц. Это означает, что наборы логики этого семейства могут применяться в широком спектре материнских плат с процессорными разъёмами Socket 939, Socket 754 или даже Socket 940.В заключение, осталось сказать о тех модификациях, которые существуют в рамках семейства чипсетов nForce4. Самой старшей моделью в этой линейке наборов системной логики является NVIDIA nForce4 SLI, нацеленный на пользователей-энтузиастов, способных выложить более $150 за материнскую плату. NVIDIA ориентирует этот чипсет на тех потребителей, для которых может быть актуально использование пары видеокарт в режиме SLI. Для этого данный набор логики предоставляет наибольшую гибкость в части конфигурирования линий PCI Express x16. Этот чипсет позволяет разбить одну шину PCI Express x16 на две шины PCI Express x8, благодаря чему становится возможным использование в системе двух видеокарт с интерфейсом PCI Express. Вариант конфигурирования шины PCI Express x16 на материнской плате определяется путём установки специальной платы-перемычки.
Средней моделью в семействе nForce4 служит чипсет nForce4 Ultra. Он рассчитан на использование в основе материнских плат стоимостью от 100 до 150 долларов. Этот набор логики обладает всеми вышеперечисленными свойствами за исключением возможности переключать режимы работы шины PCI Express x16. То есть, данный чипсет рассчитан исключительно на конфигурации с одной графической картой. Впрочем, некоторые хитрые производители материнских плат умудряются создавать платы на базе nForce4 Ultra с поддержкой SLI, объединяя для второй видеокарты две или четыре шины PCI Express x1.
Младшая модель для недорогих решений – это обычный nForce4. Бюджетность этого чипсета проявляется в двух вещах: во-первых, в нём отключено аппаратное средство сетевой безопасности ActiveArmor, а во-вторых, в обычном nForce4 отсутствует поддержка Serial ATA II.

Слайд 63NVIDIA nForce 4
Сводная таблица по основным характеристикам семейства чипсетов NVIDIA
nForce 4:

Слайд 64Последние разработки AMD
Технология Pacifica
Технология PowerNow!
Dual Stress Liner
90 нм
техпроцесс в Athlon 64
0.065 мкм техпроцесс
Мобильные процессоры
Двухядерные процессоры AMD

Слайд 65Технология Pacifica
Технология Pacifica разрабатывается с целью возможности эмуляции на
одном компьютере нескольких виртуальных машин. То есть, фактически, благодаря этой
технологии пользователи получат возможность запускать на одном PC несколько операционных систем одновременно, каждая из которых может решать свои конкретные задачи. Сложность реализации данной технологии состоит в том, что операционные системы, включая Windows, работают в «нулевом кольце», то есть взаимодействуют непосредственно с аппаратным обеспечением. Благодаря технологии Pacifica станет возможным разделение аппаратных ресурсов между несколькими операционными системами без какого-либо ущерба для функционирования системы.15 Февраля 2005 года компания AMD заявила о намерениях реализовать программную технологию виртуализации для 64-битной платформы Linux. Ранее считалось, что первыми носителями технологии станут двуядерные процессоры второго поколения, использующие разъем Socket M2.
Теперь же знакомство с полной версией официального пресс-релиза позволяет обнаружить следующую интересную фразу: Feature enhancements are also planned for future single-core and dual-core AMD64 processors that will further leverage the performance of 64-bit virtualization software. Другими словами, AMD открыто признается в намерениях внедрить технологию виртуализации в одноядерных процессорах семейства AMD64.

Слайд 66Технология Pacifica
Возможно, существующие 0.09 мкм ядра во второй половине
этого года просто получат новую ревизию, которая обеспечит поддержку Pacifica. Например, начинающий экспансию на рынок степпинг E0/E4 отличается поддержкой набора команд SSE3. Аналогичным образом в будущих степпингах может появиться и поддержка Pacifica, ведь ждать наступления 2006 года для этого совсем не обязательно. Тем более, что Intel собирается представить процессоры с поддержкой конкурирующей технологии Vanderpool уже во второй половине этого года. Характерно, что виртуализация от Intel тоже не подразумевает обязательного наличия двух процессорных ядер.
Слайд 67 Технология PowerNow!
Технология энергосбережения PowerNow! предназначена для серверных
процессоров AMD Opteron.Использование PowerNow! позволит снизить типичный уровень энергопотребления каждого
процессора до 30 Вт. Технология будет снижать множитель процессора автоматически или по требованию пользователя, причем предельное снижение может достигать десяти шагов по 200 МГц каждый. По сути, в случае необходимости процессор Opteron может работать на частоте 200 МГц, экономя электроэнергию.
Слайд 68Dual Stress Liner
В конце 2004 году компании AMD и IBM
анонсировали очередной технологический прорыв в области увеличения производительности транзисторов. Разработанная инженерами обеих компаниями технология, получившая название Dual Stress Liner, позволила увеличить скорость срабатывания полупроводниковых транзисторов на 24%.
Слайд 69Dual Stress Liner
Суть данной технологии проста: фактически, Dual Stress Liner
аналогичен технологии растянутого кремния, освоенной компанией Intel вместе с внедрением своего техпроцесса с нормами 90 нм. То есть, идея Dual Stress Liner состоит в применении кремния с деформированной для увеличения скорости срабатывания транзисторов и уменьшения их тепловыделения атомной решеткой. В одном случае атомы кремния "растягиваются", а в другом – "сжимаются" путём их помещения на подложку с растянутой либо сжатой кристаллической решёткой. Отличия же Dual Stress Liner от растянутого кремния, используемого Intel, состоят в том, что технология от AMD и IBM применима к транзисторам обоих типов, NMOS и PMOS (c n- и p- каналами) только лишь с использованием нитрида кремния, без необходимости прибегать к дорогому и экзотичному кремниево-германиевому соединению.Благодаря такой двойственности, выигрыш от технологии Dual Stress Liner превышает эффект от использования растянутого кремния в технологическом процессе Intel. В то время как Dual Stress Liner позволяет нарастить скорость срабатывания транзисторов на 24%, аналогичный показатель для технологии растянутого кремния составляет лишь 15-20%. И, что немаловажно, новая технология от AMD и IBM не вызывает снижения процента выхода годных полупроводниковых кристаллов и не увеличивает их себестоимость. Новое процессорное ядро Venice стало первым опытом AMD по практическому применению Dual Stress Liner в процессорах для настольных PC. Именно эта новая технология, которая используется одновременно с уже хорошо зарекомендовавшей себя технологией SOI (silicon-on-insulator), обуславливает возможность достижения процессорами с ядром Venice более высоких тактовых частот. Согласно ожиданиям инженеров AMD, одновременное применение Dual Stress Liner и SOI, должно позволить увеличить частотный потенциал процессоров Athlon 64 примерно на 16%. То есть, в абсолютном исчислении это означает, что процессоры с ядром Venice cмогут иметь штатные тактовые частоты, достигающие 2.8 ГГц.

Слайд 7090 нм техпроцесс в Athlon 64
Начиная с 17 августа 2004г.,
компания AMD начала поставки мобильных процессоров семейства Athlon 64, производимых
по 90 нм технологии, а с 15 сентября в магазинах начинают появляться и процессоры Athlon 64 для настольных систем, в основе которых лежат обновлённые 90 нм ядра. Таким образом, 90 нм технология оказалась освоенной AMD без каких бы то ни было задержек, а точно в соответствии с ранее намеченным планом.Переход на использование 90 нм технологического процесса AMD запланировала во всех секторах рынка. План этот на данный момент выполнен на две трети: 90 нм ядра Oakville и Winchester уже применяются в серийных процессорах для мобильных и настольных компьютеров соответственно.
Основными отличительными чертами ядра Winchester, помимо 90 нм техпроцесса, является кеш-память второго уровня объёмом 512 Кбайт и двухканальный контроллер памяти, поддерживающий DDR400 SDRAM. Таким образом, 90 нм ядро Winchester можно считать аналогом 130 нм ядра NewCastle, используемого в первую очередь в Socket 939 процессорах. Поэтому, совершенно неудивительно, что первыми процессорами Athlon 64, в которых нашло применение ядро Winchester, также стали CPU для Sockets 939 систем.
При проектировании ядра Winchester инженеры AMD не стали прибегать к редизайну. Фактически, Winchester остался тем же NewCastle, просто переведенным на более совершенный техпроцесс с нормами производства 90 нм. Однако отдельные минорные архитектурные улучшения в этом ядре всё же присутствуют, благодаря чему его производительность по сравнению с производительностью предшественника слегка возросла.

Слайд 7190 нм техпроцесс в Athlon 64
Для сравнения приведем изображение литографических
пластин с расположенными на них ядрами процессоров NewCastle и Winchester,
выполненных по 130нм и 90нм технологическому процессу соответственно, а также самих процессоров:
Слайд 7290 нм техпроцесс в Athlon 64
Объясняется всё простым расчётом. 130
нм ядро NewCastle имеет площадь 144 мм2. Площадь нового ядра
Winchester, благодаря использованию 90 нм технологического процесса, уменьшилась до 84 мм2. Таким образом, применение 90 нм технологии позволило AMD уменьшить площадь ядра на 42%. Учитывая, что на заводе Fab30 в Дрездене, на котором производятся и старые ядра NewCastle, и новые ядра Winchester, используются пластины диаметром 200 мм, новый технологический процесс даёт возможность получить на 77% больше процессорных ядер с пластины.Поскольку сложившаяся на процессорном рынке ситуация такова, что у AMD нет нужды наращивать тактовые частоты своих процессоров, AMD решила начать внедрение 90 нм ядер Winchester не со старших, а с младших моделей своих CPU, тем более что тому есть чёткое экономическое обоснование. Первые процессоры, основанные на ядре Winchester, предназначаются для использования в Socket 939 системах, обладают частотами от 1.8 до 2.2 ГГц и имеют рейтинги 3000+, 3200+ и 3500+. То есть, с появлением нового 90 нм ядра компания AMD значительно расширила линейку Athlon 64 для Socket 939 систем вниз.
Помимо снижения себестоимости процессоров линейки Athlon 64, выпуск 90 нм ядер позволил также уменьшить и их тепловыделение. В то время как максимальное тепловыделение процессоров, построенных на 130 нм ядрах NewCastle, составляло 89 Вт, аналогичная характеристика процессоров, базирующихся на 90 нм ядрах Winchester, составляет всего лишь 67 Вт. Таким образом, AMD успешно обошла проблемы с высокими токами утечки, с которыми столкнулась Intel при выпуске своего 90 нм ядра Prescott: как известно, тепловыделение процессоров Pentium 4 на базе ядра Prescott не уменьшилось по сравнению с тепловыделением Pentium 4, построенных на базе 130 нм ядра Northwood.

Слайд 7390 нм техпроцесс в Athlon 64
С начала апреля 2005 года компания
AMD планирует начать программу по прекращению выпуска процессоров серии Athlon 64, в основе которых лежат ядра, производимые по устаревшему технологическому процессу. За тот срок, который прошёл с момента появления первых CPU ядром Winchester, инженеры компании проделали большую работу. Было спроектировано новое 90 нм ядро Venice (ревизия E3), которое должно отправить старые 130 нм ядра на свалку истории. Большие надежды, возлагаемые на обновлённое ядро, опираются на тот факт, что AMD начинает внедрять усовершенствованный технологический процесс, который как раз используется для производства ядер Venice. В результате, ядро Venice должно позволить не только заменить Winchester в младших моделях Athlon 64, добавив им новые функциональные возможности, но и прийти на смену ядрам Newcastle и Clawhammer, применяемым в наиболее быстрых модификациях этого процессорного семейства. Более того, появление ядра Venice открывает зелёную улицу и для выпуска более скоростных версий процессоров Athlon 64. Ожидается, что в недалёком будущем AMD представит общественности новые Athlon 64 4200+ и Athlon 64 FX-57, в которых также найдёт применение ядро Venice и ядро San Diego, являющееся аналогом Venice с увеличенной кеш-памятью второго уровня. Таким образом, несмотря на то, что AMD не пожелала шумно афишировать факт появления нового ядра, открывающего широкие перспективы для дальнейшего развития линейки Athlon 64, обойти это событие стороной невозможно. Тем более что помимо возросшего частотного потенциала, ядро Venice добавляет в процессоры Athlon 64 и поддержку набора инструкций SSE3, внедрённого в конкурирующие CPU семейства Pentium 4 в прошлом году с появлением ядра Prescott. Именно поэтому мы решили подготовить данный материал, в котором подробно посмотрим на новое ядро для процессоров Athlon 64.
Слайд 7490 нм техпроцесс в Athlon 64
В первую очередь следует отметить тот
факт, что в процессорном ядре Venice инженеры AMD расширили набор поддерживаемых SIMD инструкций. Теперь, подобно процессорам Pentium 4 на базе ядра Prescott, новые Athlon 64 с ядром Venice будут поддерживать набор команд SSE3. Впрочем, уместным будет напомнить, что SSE3 представляет собой не законченное множество команд, а лишь небольшое дополнение к SSE2. Так, набор команд SSE3, реализованный в Venice, включает 11 новых инструкций, в числе которых:ADDPS, HSUBPS, HADDPD, HSUBPD - горизонтальные операции с SSE2 регистрами, почему-то забытые при разработке набора инструкций SSE2. Данные команды могут быть чрезвычайно полезны при обработке 3D графики, так как позволяют упростить вычисление такой распространенной величины, как скалярного произведения векторов. ADDSUBPS, ADDSUBPD, MOVSHDUP, MOVSLDUP, MOVDDUP – инструкции для работы с комплексными числами. Данные команды могут оказаться полезными при расчете волновых процессов и работе со звуком, в общем там, где применятся быстрое дискретное преобразование Фурье. FISTTP – новая инструкция арифметического сопроцессора, позволяющая преобразование стека сопроцессора к целому типу. Данная операция по каким-то непонятным причинам в системе команд x87 ранее отсутствовала. LDDQU – инструкция для загрузки 128-битных невыровненных данных. Может оказаться полезной для ускорения процесса сжатия видео.
В результате, новые процессоры семейства Athlon 64, в которых применено ядро Venice, обладают наиболее полным на сегодняшний день набором SIMD-инструкций, включающим системы команд 3DNow!, SSE2 и SSE3. Впрочем, ожидать качественного скачка производительности от появления в Athlon 64 системы команд SSE3 вряд ли стоит. Арсенал приложений, использующих команды SSE3, пока, к сожалению, очень ограничен и весьма специфичен.

Слайд 7590 нм техпроцесс в Athlon 64
С выходом каждого нового процессорного ядра
для Athlon 64 инженеры AMD проводят дальнейший тюнинг встроенного в CPU контроллера памяти. Причём, цель этого процесса состоит не только в наращивании производительности, но и в расширении совместимости контроллера памяти с различными модулями DIMM и их конфигурациями. Так предыдущее 90 нм ядро процессоров Athlon 64, Winchester, имело ограниченную работоспособность при использовании четырёх модулей DDR400 SDRAM. Так, при установке в систему с процессором Athlon 64 на ядре Winchester четырёх односторонних модулей памяти, работа с ними допускалась лишь при использовании тайминга 2T, что приводило к снижению производительности относительно обычного уровня на несколько процентов. При использовании же четырёх двухсторонних модулей память в режиме DDR400 работать не могла вообще: её частота автоматом снижалась до 333 МГц. В новом ядре Venice инженеры AMD обещали исправить это положение и обещание своё сдержали. Процессоры Athlon 64 на базе нового ядра могут работать с четырьмя односторонними модулями DDR400 SDRAM без каких бы то ни было ограничений, а при использовании в системе четырёх двухсторонних модулей памяти DDR400 допускается их работа на частоте 400 МГц, но при использовании тайминга 2T. Помимо расширения совместимости контроллера памяти процессорного ядра Venice, также была проделана работа и по увеличению его производительности. Среди реализованных в Venice твиков следует отметить усовершенствование аппаратного механизма предвыборки данных и увеличение числа write combining буферов с двух до четырёх. Благодаря этим улучшениям процессоры Athlon 64 на базе нового ядра Venice должны слегка превосходить по производительности работающие на такой же тактовой частоте аналоги, в основе которых лежат более ранние ядра. Причём, преимущество в производительности будет становиться более осязаемым, если в системе установлено четыре модуля памяти.
Слайд 7690 нм техпроцесс в Athlon 64
Появление нового 90 нм ядра Venice позволит
AMD полностью модернизировать линейку процессоров Athlon 64 для Socket 939. Если предыдущее ядро Winchester использовалось лишь в CPU с тактовыми частотами до 2.2 ГГц, то Venice должно исправить эту ситуацию. С 4 апреля AMD начинает поставки процессоров Athlon 64 для Socket 939 на ядре Venice с рейтингами от 3000+ до 3800+. Причём, модели процессоров с ядром Venice и рейтингами 3000+, 3200+ и 3500+ приходят на смену Athlon 64, использующим ядро Winchester, а новая модель Athlon 64 с рейтингом 3800+ - заменит предшественника с ядром Newcastle. Не будет обойдён тотальной заменой ядер на более прогрессивное и Athlon 64 4000+, в основе которого в настоящее время используется ядро Clawhammer с кеш-памятью второго уровня объёмом 1 Мбайт. С 15 апреля AMD начнёт поставки обновлённых Athlon 64 4000+ с ядром San Diego, являющимся, по сути, полным аналогом Venice с увеличенной кеш-памятью второго уровня.Что же касается теплового пакета, то новое ядро Venice на первый взгляд имеет такие же характеристики типичного тепловыделения, как и предшествующие ядра. Однако, это не совсем так. Дело в том, что Venice имеет несколько больший запас по наращиванию тактовой частоты при сохранении тепловыделения в рамках заданного теплового пакета. Так, будущие модели Athlon 64 с ядром Venice, работающие на частоте 2.6 ГГц, будут иметь типичное тепловыделение 89 Вт, а переход на следующую ступень теплового пакета, 104 Вт, если и произойдёт, то только по достижению частоты в 2.8 ГГц. Подводя итог, следует отметить, что, несмотря на достаточно существенные изменения, произошедшие в ядре Venice, ни площадь ядра, ни число транзисторов в нём по сравнению с Winchester не изменились.

Слайд 7790 нм техпроцесс в Athlon 64
Чтобы обобщить вышесказанное, привёдём полный перечень Socket 939
процессоров Athlon 64, в основе которых лежат новые и старые процессорные ядра, доступных и становящихся доступными в настоящее время:
Слайд 780.065 мкм техпроцесс
Производство 0.065 мкм процессоров начнется в первой половине
2006 года, когда будет запущена Fab 36. Уже сейчас начался
монтаж оборудования, и оснащение этой 300 мм фабрики идет в соответствии с намеченным графиком. Помогать в производстве процессоров AMD к тому времени начнет сингапурская компания Chartered Semiconductor. Освоит ли Fab 7 производство 0.065 мкм процессоров одновременно с Fab 36, сказать сложно, но дефицит процессоров такие меры позволят снять однозначно.Компания IBM является "технологическим донором" не только для AMD и Chartered, но и Samsung и Infineon. Поскольку определенных успехов в освоении 0.065 мкм технологии IBM уже добилась, имеет смысл говорить о первых итогах. В частности, 0.065 мкм техпроцесс позволит компаниям увеличить производительность транзисторов на 35%.
IBM и AMD будут интенсивно использовать в рамках 0.065 мкм техпроцесса не только "растянутый кремний", но и "растянутый германий", low-k диэлектрики. Ядра процессоров будут состоять из 10 слоев, медные межсоединения найдут свое применение. Все эти меры помогут увеличить частотный потенциал и снизить энергопотребление.

Слайд 79Мобильные процессоры
Недавно запущенный в серийное производство процессор Low Power Mobile
Athlon 64 3000+ на 0.09 мкм ядре Oakville будет оставаться
старшим в семействе вплоть до первого квартала 2005 года.Затем на смену Oakville придет ядро Lancaster, выпускаемое по тому же 0.09 мкм техпроцессу с использованием SOI. Отличие Lancaster будет заключаться в увеличенном с 512 Кб до 1 Мб кэше второго уровня.
Первые процессоры на ядре Lancaster будут работать на частотах 2.0 ГГц (Low Power Mobile Athlon 64 3200+) и 2.2 ГГц (Low Power Mobile Athlon 64 3400+). Очевидно, 0.09 мкм техпроцесс к тому моменту обретет нужную зрелость, чтобы позволить наращивать тактовые частоты и увеличить объем кэша при сохранении прежнего уровня TDP в 35 Вт.
В первой половине следующего года также выйдут 0.09 мкм версии Mobile Sempron на ядре Georgetown и Low Power Mobile Sempron на ядре Sonora.
AMD Turion – новая линейка процессоров AMD, предназначенная для рынка сверхпортативных ПК, которая, ко всему прочему, поддерживает технологию, напоминающую Centrino. Судя по всему, Turion станут логическим дополнением Sempron (32-разрядных процессоров для рынка систем начального уровня) и Mobile Athlon (32/64-разрядный процессор для high-end систем, а также ноутбуков класса замены настольных ПК). По словам Бара Махони, менеджера по маркетингу мобильных решений AMD, «ряд производителей систем в настоящее время тестируют чипсет, дабы удостовериться, что он поддерживает все существующие стандарты беспроводных сетей».

Слайд 80Мобильные процессоры
Процессор Turion 64 является полнофункциональной версией Athlon 64 под
Socket 754 и наследует все его характеристики - интегрированный контроллер памяти (одноканальной DDR400), поддержку 64-битного расширения AMD64, технологию системной шины Hyper-Transport, защиту от исполнения вирусоподобного кода под Windows XP SP2 (NX-бит). Для активного управления электропитанием используется технология PowerNow! (частота и напряжение питание процессора меняется динамически в зависимости от нагрузки, дополнительно в режиме максимального энергосбережения при переходе на питание от батарей частота может ограничиваться заданным значением).Переход на новый степпинг добавил ко всему вышеперечисленному поддержку последней версии потокового расширения - SSE3 и оптимизированный контроллер памяти, а обновленный технологический процесс (90 нм, SOI с использованием технологии «растянутого» кремния) позволил снизить потребляемую мощность. На данный момент чипы сортируются на две группы, в зависимости от минимального напряжения, на котором достигается стабильная работа на штатной частоте. Первая группа рассчитана на использование в ноутбуках, способных отвести 25 Вт от процессорного узла, «менее удачные» чипы из второй группы рассчитаны на ноутбуки, способные справится с 35 Вт.

Слайд 81Мобильные процессоры
Модельный ряд Turion64 на момент запуска включает семь
моделей с частотой от 1,6 до 2,0 ГГц и объемом кэш-памяти второго уровня 512-1024 Кбайт, причем градация внутри линейки предусматривает и так называемую «степень мобильности» отраженную в маркировке.Что касается Turion-чипсетов, их будет несколько. Причем на данный момент доступно уже пять. Чипсет Radeon Xpress 200M от ATI поддерживает интегрированную графику уровня Radeon X300 с поддержкой DirectX 9.0. Есть возможность выделения буфера для нужд графического ядра в оперативной памяти с обращением к нему через выделенный канал по технологии HyperMemory, более того - допускается и установка отдельной видеопамяти объемом до 128 Мбайт на материнскую плату! Из интерфейсов доступно Serial ATA (поддержка дисковых RAID-массивов уровней 1и 0), восьмиканальный звуковой кодек, Gigabit Ethernet контроллер, поддержка шины HyperTransport с частотой 1 ГГц, восемь портов USB 2.0, четыре слота PCI Express x1 и до семи слотов PCI. За экономию энергии ответственна технология PowerPlay 5.0 (отключение простаивающих устройств и снижение частоты графического ядра).
Чипсет VIA K8N800A располагает менее мощной интегрированной графикой - ядро S3 Graphics UniChrome Pro, видеобуфер может располагаться только в системной памяти и обращение графического ядра в память ведется через общий канал (интегрированный в центральный процессор контроллер). Поэтому более вероятно его использование в недорогих и облегченных моделях, из полезных опций отметим аппаратную поддержку декодирования MPEG2. Оптимизацией расхода энергии занимается технология Stutter Mode. Южный мост VT8237 поддерживает Serial ATA наравне с Parallel ATA-133, до восьми USB 2.0 портов, 8-канальный аудиоконтроллер и Fast Ethernet. Частота шины HyperTransport - 800 МГц. Чипсет VIA K8N800 является копией предыдущего, за исключением интегрированной графики, ибо рассчитан на установку дискретной AGP-карты. В апреле 2005 года ожидаются поставки чипсета K8N890, отличающегося от K8N800A увеличенной до 1 ГГц частотой HyperTransport и новым графическим ядром DeltaChrome с поддержкой DirectX 9.0, одного порта PCI-Express 16x и двух PCI-E 1x.

Слайд 82Двухядерные процессоры AMD
Как известно, оба ведущих производителя x86 процессоров, AMD
и Intel обозначили своё стремление в недалёком будущем перейти к
выпуску CPU с двумя ядрами. Это – вполне естественное отражение современных тенденций в процессоростроении. Дальнейшее наращивание тактовых частот становится всё более и более сложным процессом, сопряженным с различными трудностями, поэтому в ход идут совершенно иные методы достижения более высокой производительности.Архитектурно, реализация двухядерности предусматривается AMD наиболее очевидным образом. В будущих процессорах архитектуры AMD64 с двумя ядрами дублированию будет подвергнуто само вычислительное ядро и кэш-память, в то время как контроллеры, выполняющие функции северного моста (такие как контроллер памяти и контроллер HyperTransport), останутся в двухядерных процессорах в единственном экземпляре. В этой связи ключевое значение начинает играть блок System Request Queue (SRQ), на который будет возлагаться обязанность арбитража потоков команд и данных между двумя ядрами.
Блок SRQ уже присутствует в современных процессорах с архитектурой AMD64, поэтому расширение его функциональности для обслуживания двух ядер вряд ли вызовет у инженеров AMD какие-либо проблемы.

Слайд 83Двухядерные процессоры AMD
Первые процессоры от AMD, имеющие два ядра, будут
нацеливаться на рынок серверов и высокопроизводительных рабочих станций. Это означает,
что сначала двухядерные CPU появятся в составе семейства Opteron. Именно поэтому такие процессоры будут иметь два L2 кеша по 1 Мбайту, то есть суммарный объём кеш-памяти будущих Opteron составит 2 Мбайта. Следует заметить, что с выпуском двухядерных процессоров AMD не намеревается внедрять использование более современных разновидностей памяти типа DDR2 SDRAM или шину HyperTransport 2.0. То есть, Opteron с двумя ядрами будут поддерживать обычную DDR SDRAM и иметь три привычных шины HyperTransport. Это означает, что нет никаких причин, по которым будущие двухядерные Opteron будут несовместимы с представленными на рынке одноядерными. То есть, такие процессоры с парой ядер будут выпускаться, по всей видимости, в том же самом Socket 940 исполнении и будут совместимы (с некоторыми оговорками, касающимися тепловыделения и энергопотребления) с имеющимися материнскими платами.Что же касается процессоров AMD для рынка настольных систем, то для него двухядерные процессоры предложены будут, по всей видимости, не столь скоро. Во-первых, AMD не видит реальной необходимости в продвижении двухядерных архитектур на рынок настольных PC. Во-вторых, на пути использования процессоров с двумя ядрами в в настольных системах может встать их высокое тепловыделение, с которым в серверах и рабочих станциях бороться несколько проще. То есть, если процессоры Opteron с двумя ядрами должны будут появиться с вводом в эксплуатацию технологического процесса с нормами 90 нм, то, судя по всему, двухядерные Athlon 64 смогут стать реальностью лишь с переводом производства на использование процесса с нормами 65 нм. Тем не менее, исключать возможность появления Athlon 64 FX с двумя ядрами, производимого по технологии 90 нм, всё же не стоит. Двухядерный Athlon 64 FX, как достаточно редкий и дорогой CPU для пользователей-беспредельщиков, вполне может быть выпущен уже в следующем году, хотя пока AMD не озвучивала такие планы.

Слайд 84Двухядерные процессоры AMD
31 августа 2004 на прошедшей в США презентации
был представлен четырехсокетный сервер HP ProLiant DL585, содержащий четыре двуядерных
0.09 мкм процессора Opteron. По сути, общее число ядер в этой системе достигло 8 штук. Кстати, AMD считает более корректным называть серверы по количеству процессорных разъемов, а не собственно процессоров (и надо сказать, что Microsoft в итоге поддержала AMD в этом вопросе). Выставленный на презентации сервер еще раз доказал, что двуядерные версии Opteron будут устанавливаться в материнские платы с разъемами Socket 940 безо всяких затруднений, для обеспечения совместимости потребуется лишь обновить BIOS.Выше приведены фотография двуядерного 0.09 мкм процессора Opteron и сравнительное фото с одноядерными процессорами (слева направо): 0.13 мкм Opteron, 0.09 мкм Opteron, двуядерный 0.09 мкм Opteron.

Слайд 85Двухядерные процессоры AMD
В заключение, несколько слов следует сказать о себестоимости
двухядерных процессоров Opteron, которые будут выпускаться по 90 нм техпроцессу.
Как показывают подсчёты, стоимость этих процессоров окажется не выше стоимости сегодняшних 130 нм процессоров Opteron, несмотря на достаточно серьёзный рост числа транзисторов. Дело в том, что при переводе производства на 90 нм технологию, площадь одного ядра сокращается примерно на 40%. Учитывая, что в двухядерных процессорах дублированы будут только L2 кеш и вычислительное ядро, а контроллеры HyperTransport и памяти останутся в единственном экземпляре, площадь ядра двухядерных Opteron, произведённых по технологии 90 нм, составит не более 197 кв. мм. Современные же Opteron имеют площадь ядра 193 кв. мм, что как раз и говорит о реальной возможности для AMD начать выпуск процессоров с двумя ядрами, не дожидаясь внедрения 65 нм техпроцесса.
Слайд 86Заключение
Впервые с момента появления набора команд 3DNow! (1998) AMD предложила
принципиально новое расширение (да еще какое!), отняв при этом инициативу
у главного конкурента - корпорации Intel.Архитектура AMD x86-64 - очень интересный подход к переходу на 64-разрядные вычисления, и еще слишком рано, чтобы решать судьбу этой архитектуры. Основным в ней является совместимость с целью облегчить переход, почему она и является всего лишь расширением существующей архитектуры. Как говорят представители AMD, "x86-64 расширяет существующие механизмы, вместо создания новых".
Одно можно сказать точно - архитектура AMD x86-64 получилась очень удачной и заслуга в этом не только наличия набора команд х86-64, а того, что AMD, взяв за основу удачный К7, смогла не только улучшить все сильные стороны этой архитектуры, но и практически избавилась от слабых.
Новые процессоры были поддержаны и ведущими производителями наборов системной логики, благодаря чему Athlon 64 в паре с NVIDIA nForce 4 является наиболее функциональной и производительной платформой на данный момент.
Грядущее пришествие двуядерных процессоров позволит с новой силой раскрыться инновациям AMD K8, среди которых необходимо отметить встроенный контроллер памяти и высокопроизводительную шину Hyper Transport, которая изначально закладывалась в архитектуру этого семейства процессоров с перспективой реализации многоядерной архитектуры.
Архитектура AMD x86-64 получилась весьма удачной и заслуга в этом не только наличия набора команд х86-64, а того, что AMD, взяв за основу удачный К7, смогла не только улучшить все сильные стороны этой архитектуры, но и практически избавилась от слабых.
С уверенностью можно сказать, что инженерные идеи, заложенные в AMD K8, безусловно, будут развиваться в дальнейшем, и мы станем свидетелями становления самой долговечной микропроцессорной архитектуры современности.
 AMD предложила принципиально")
Слайд 87P.S.
О признании
архитектуры AMD x86-64 говорит и тот факт, что один из
безусловных лидеров рынка суперкомпьютеров, компания Cray, не так давно представила два новых семейства мэйнфреймов, построенных на основе процессоров Opteron 2xx фирмы AMD. Серия XD-1 в максимальной конфигурации обладает следующими характеристиками: 144 процессора Opteron 2.4GHz, пиковая вычислительная производительность 691 Gflops, пропускная способность памяти 922 Гб/c, максимальный объем памяти – 1.2 Тб. Все это великолепие работает под управлением специально модифицированной версии Linux/AMD64, и допускает объединение в кластеры, то есть 144 вычисляющих процессора для XD-1 – не предел. Более мощное семейство XT-3 объединяет в одном корпусе уже десятки тысяч процессоров Opteron 1xx. Самая продвинутая конфигурация может содержать 30.000 процессоров данной модели, и предназначается для крупных научно-исследовательских лабораторий и институтов. Думаю, каждому из обладателей настольной конфигурации на Opteron приятно будет осознать, что в его машине работает маленький кусочек суперкомпьютера.
Слайд 88Методика использования демонстрационного пособия
Представленное пособие может быть использован в процессе
обучения для дисциплин:
Аппаратные средства вычислительной техники;
Архитектура микропроцессора;
Языки ассемблера.
Согласно программе дисциплины «Аппаратные средства вычислительной техники» для специальности 075200 – Компьютерная безопасность, представленное пособие целесообразноиспользовать при изучении темы №8 – «Микропроцессорная техника»
Тема: Исследование особенностей архитектуры семейства процессоров AMD K8.
Цель занятия: Рассмотреть архитектурные и структурные особенности процессоров AMD K8, принципы реализации архитектуры х86-64.

Слайд 89Контрольные вопросы
В процессе исследования представленного материала предлагается ответить на следующие
вопросы:
1. Сколько стадий имеет целочисленный конвейер процессора Athlon64?
а)
10б) 12
в) 17
2. Сколько новых регистров общего назначения получил процессор Athlon64?
а) 8
б) 16
в) 32
3. Какова ширина адресной шины процессора Athlon64?
а) 40
б) 48
в) 64
4. Какая часть ядра AMD K7 подверглась наибольшей переработке при переходе к архитектуре AMD K8, что, в свою очередь, вызвало удлинение конвейера?
а) Буфер быстрого преобразования адреса
б) Блок предсказания переходов
в) Декодер
5. Сколько встречных шин соединяют кэш 1-го и 2-го уровня процессора Athlon64 и какова их разрядность?
а) 1 шина с разрядностью 128 бит
б) 2 шины с разрядностью 64 бита каждая
в) 2 шины с разрядностью 128 бит каждая

Слайд 90Контрольные вопросы
6. Какова пропускная способность шины Hyper Transport, применяемой в
процессорах AMD K8?
а) 6,4Гб/с или 10Гб/с
б)
6,4Гб/с или 8Гб/св) 8Гб/с или 10Гб/с
7. Какие конструктивы процессоров AMD K8 имеют двухканальный контроллер памяти?
а) S754 и S940
б) S754 и S939
в) S939 и S940
8. Какова цель внедрения в процессоры AMD K8 технологии Pacifica?
а) возможность эмуляции на одном компьютере нескольких виртуальных машин
б) снижение тепловыделения
в) повышение защищенности ЭВМ от вирусов
9. Улучшение какого параметра процессоров преследует технология PowerNow! ?
а) частотного потенциала
б) энергосбережения
в) тепловыделения
10. Какие компоненты процессоров архитектуры AMD64 с двумя ядрами подвергнуты дублированию?
а) ядро и контроллер Hyper Transport
б) ядро и контроллер памяти
в) ядро и кэш-память